

Agent Amnesia and Broken Data Models
Building to learn: a solution to the memory, collaboration and data model problems in OpenClaw


If you’ve been following the trond.ai Build to Learn series, you’ll have heard of Stella. Stella is an OpenClaw setup running on a Mac Mini in my office. She (yes, we anthropomorphize her) manages our family’s: calendar, smart home, kids’ schedules, recipes, travel planning, reminders, car service, appliance maintenance, and so much more. She’s genuinely useful and has quickly become a trusted partner in our home.
But there are problems with Stella that need fundamental improvements in my OpenClaw setup to address. Let’s talk about the problems and the solution I’ve been working on building this week.
Assistant Amnesia
Stella is frustratingly forgetful. I’ve had to remind her about projects we were working on together, and sometimes she’d lose the train of thought mid-conversation. Especially if it spanned a 30 minute boundary when her memory would get collected and updated. New session, clean slate. I’d re-explain context, she’d reload what we talked about, we’d rebuild momentum, and then the conversation would hit the context limit and compact. Details gone. Thread lost. Start over. GAH!
I thought AI hallucinations were annoying. This is 1000x worse!

There are countless people working on solutions to better agent memory across the OpenClaw community. The stock solution uses a MEMORY.md file that’s updated periodically based on conversational context within each heartbeat process. This context is passed into the agent’s memory each time a session is initiated, which is supposed to preserve details and progress in a seamless way. But in reality, the compaction process loses too much detail and biases too much on recency.
I poked around with a lot of the solutions people were building to try to address this problem. Some are very well designed, like supermemory.ai, featuring RAG systems with complex vector databases and advanced workflows to integrate into your agent. But they didn’t really solve my problem. I wanted something that kept data in a format I could easily read and modify and something that worked better with my collaboration model.
Collaboration Nightmare
The forgetting is one thing. But when you’re trying to collaborate across devices, sessions and people it all gets just so much worse. I use Obsidian as a thinking and organization tool. Stella runs on a separate machine without access to the local vault. Those two worlds don’t talk to each other. If she learns something from a conversation, my notes don’t know about it. If I edit a note about a project, she doesn’t see the change until I paste it into a chat. Working together on things was like playing telephone with project context.
I see this as a fundamental flaw with chat-based AI: everything is assumed to be serial. One conversation, one thread, linear. That works fine for “what’s the weather.” It breaks immediately when you want to do real knowledge work, picking up a thread from a different device, having your AI and your notes reflect the same reality, working on something that evolves over days or weeks. Never mind projects that work across agents and people.
We kept bumping into the same wall: the AI lives in the chat. Everything important lives somewhere else. They never quite sync up. I needed a better approach. I really wanted something that would keep Stella’s memory system and my Obsidian vault in perfect sync.
Text Is a Terrible Data Model
We all know LLMs work best with text, and OpenClaw is no different. So much so, that it reminded me of the good old days of computer science when our computers were basically command line interfaces passing text between processes using unix primitives. Turns out Anthropic agrees — they’ve published research on Contextual Retrieval showing this technique outperforms RAG and vector lookup for agent memory.
This means that when Stella needs to know about my mom, she can cat a markdown file and read it like a document.That’s how most AI memory systems work. Store everything as text, search through text, return text.
But my mom isn’t a document. She’s a collection of facts, some current, some outdated, some time-bound, with relationships to other facts, timestamps, and different levels of reliability. “She’s visiting in March” is a different kind of fact than “She was born in 1951.” One expires. The other doesn’t.
Flat text files don’t know any of this. They mix it all together. An AI reading a flat file has to parse, infer, and guess what’s still true. It’s actually pretty dumb.
This is actually a solved problem in software. In 2002, Jeffrey Snover wrote the Monad Manifesto about this exact problem. He helped Microsoft design PowerShell in 2006 to implement a better approach. Unix pipes pass text between commands, so every tool has to parse the output of the previous one. PowerShell passes objects instead. Typed, structured, queryable. That’s because text is the right interface for humans but objects are a better interface for automation.
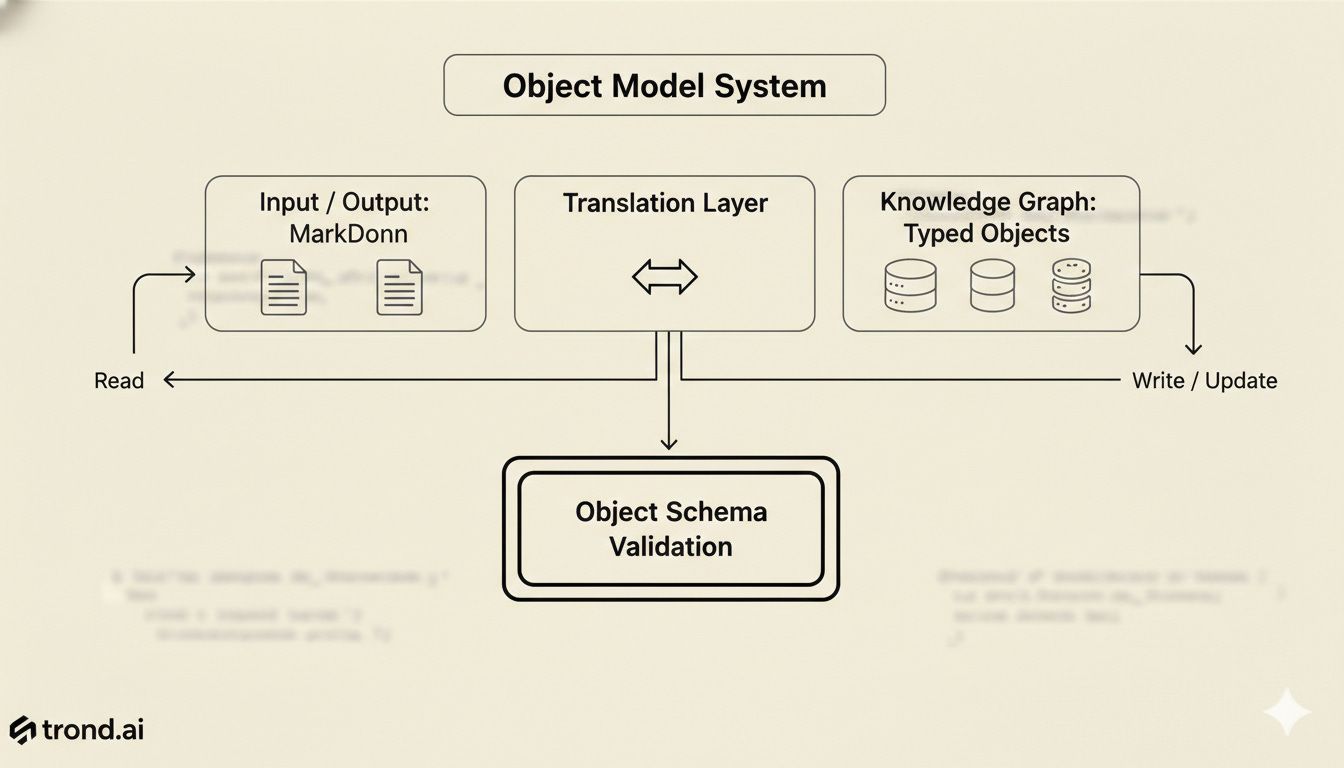
What if we applied this same approach to AI memory? Could we use the benefits of LLMs and the structure of data objects to build something even better?
Building to Learn - AgentSync
This week, I set out to learn about these three problems:
Agentic Amnesia
Borked Collaboration
Broken Object Models
Which is why I (with a lot of help from Stella) built AgentSync. AgentSync is fundamentally a knowledge graph system built on a foundation of typed objects that are automatically collected, scoped, updated and shared in real-time across my devices. Facts aren’t stored as prose. They’re stored as typed objects: what the fact is, when it was learned, where it came from, whether it’s still active, when it expires. And everything is sync’d in realtime via human readable and modifiable markdown.
When Stella needs to know details about my mom, she runs:
agentsync query people --name guriShe gets back structured data. Not a text file to interpret. A typed object to act on. Invalid states are impossible because validation happens at the write boundary. A fact that doesn’t match the schema can’t reach the knowledge graph.
The filesystem is the schema. Create a directory for a new domain and it’s automatically discovered as an entity type. We have 217 entities across 11 domains right now: people, recipes, projects, properties, conversations, subscriptions. No configuration. We just started using it and it grew. That’s its magic. When Stella extracts a fact from a conversation, it gets validated and filed automatically.
Session starts cost (virtually) zero tokens. There’s a lightweight index that shows what exists without loading anything. Stella knows she has 127 recipes without reading a single one. She loads context on demand, for whatever domain she actually needs. Sessions that used to burn 5-10K tokens on context reload now start at zero.
It’s much more efficient, accurate and flexible. And since it’s self-learning and self-healing, the system can evolve as my knowledge base expands.
Real-Time Sync With Obsidian
Structured objects fix the data model. The collaboration problem needed something else.
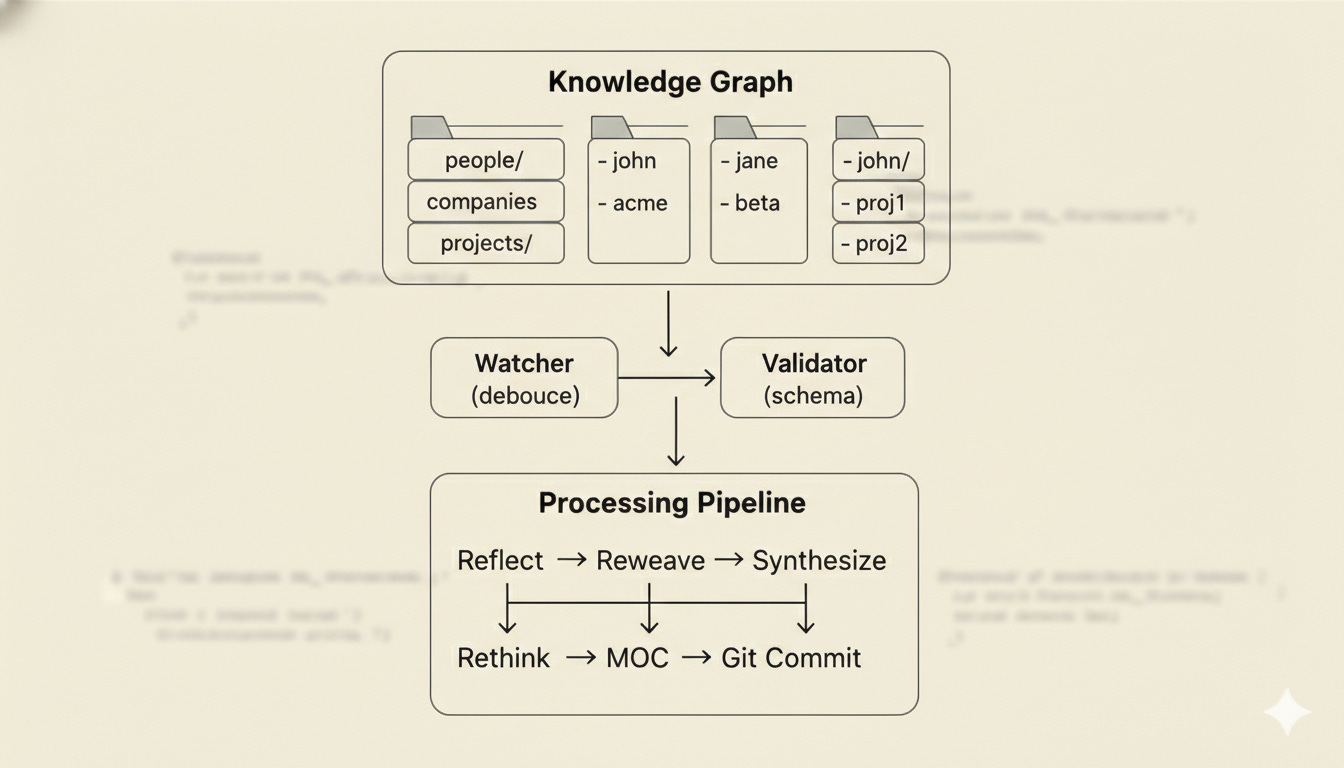
To take this on, I built a WebSocket relay using Cloudflare Workers. File changes on any configured device broadcast through the relay. Each component in the system subscribes to the relay. On Stella’s Mac Mini, we run a real-time file watcher service. On my other devices, I run a custom Obsidian plugin that keeps our shared vaults in sync. Sub-second latency, content-addressed deltas, no merge conflicts. It’s really pretty magical.
Edit a note in Obsidian. Stella sees it instantly. She learns something new in a conversation. It shows up in my vault before I open it. The files we interact with are human readable markdown. The insights they contain are instantly converted to typed objects saved in companion files built for computer readability.
Now, I can easily see anything in Stella’s vault. Update TODO files directly and implement multi-agent or multi-person collaboration workflows with complete confidence our shared memory preserves context.
The Self-Documenting Test
One cool thing about this project is that we used the system while building the system.
Every architecture decision got logged as a fact. Every deployment got tracked with a timestamp and commit hash. Every time we changed direction, we logged why. When I sat down to write this article, I ran:
agentsync query projects --search "agentsync"Complete build history. Every decision, every deployment, every pivot. The system documented its own creation in real-time, so when we needed to write about it, we didn’t have to remember anything. We just queried.
That’s not a demo. That’s the whole point.
Some numbers from five days of real use:
217 entities, zero invalid data on disk
Sessions: from 5-10K tokens to zero on startup
Sub-second sync between Mac Mini and MacBook
127 recipes, including one extracted from an Instagram reel at 11pm
Full conversation archives going back 48+ hours, searchable and compressed
Typed objects for every entity type, automatically organized and searchable
Why This Matters Now
AI assistants are going to get much better at the hard things: reasoning, planning, synthesis. The memory problem is solvable right now, with a filesystem and 1,400 lines of TypeScript.
The real unlock isn’t any single feature. It’s the combination: typed knowledge that can’t corrupt itself, zero-token session starts, real-time sync that keeps humans and AI working from the same source of truth, and conversation archives that survive compaction.
Your AI assistant shouldn’t have to re-learn who your mom is every morning. That’s a solvable problem. We just needed to actually build the solution.
AgentSync is open source on GitHub, MIT licensed, self-hostable, works with Obsidian or any file-based workflow.
If your AI is still waking up with amnesia, it doesn’t have to. We’ve learned by building AgentSync there’s a better way. Next up: project management!
GitHub: stellawuellner/agentsync
What does your AI memory setup look like? I’m curious whether others have hit the same wall or found different ways around it.