

NotebookLM’s execution stack
Extending NotebookLM to support grounded execution.

Last week, we announced a significant update to NotebookLM with the addition of an integrated cloud computer for each notebook. The announcement focused on how it helps users go deeper with research and do more within notebooks, which is the right way to frame an announcement on a large-scale Google blog. There, we’re speaking to a broad audience spanning press, users, and influencers interested in keeping tabs on what’s new at Google.
Here on my personal Substack I have a bit more editorial license, so I wanted to share a bit more about why I’m so personally excited about this update. It boils down to one question: what changes when a research tool stops being just a place to ask questions and also becomes a place where work actually happens? That is the part I find interesting here. NotebookLM is becoming a place to do real work, grounded in information you trust.
A fundamental architecture shift
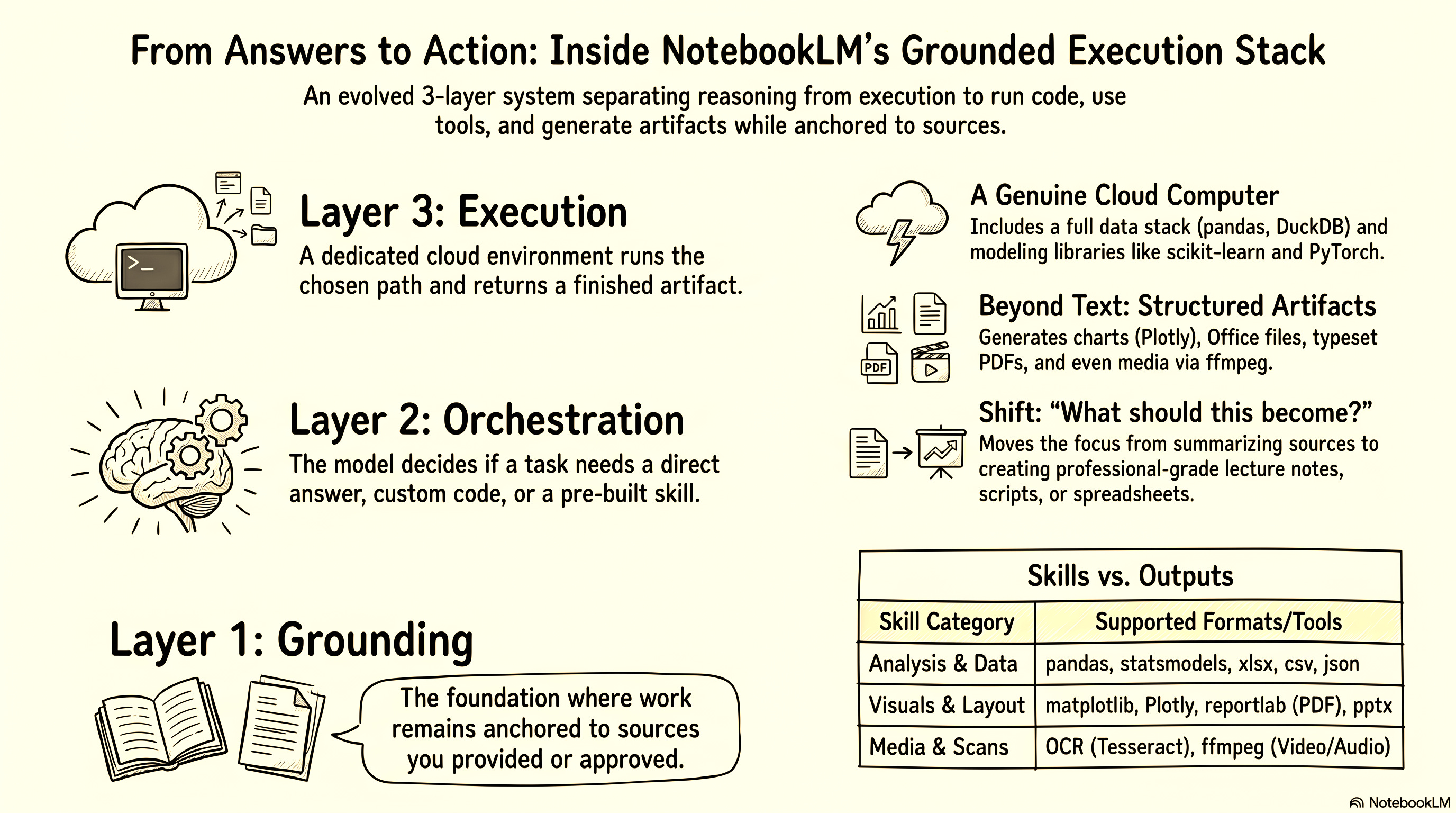
With these changes, NotebookLM now has a more explicit execution layer. Everything remains rooted in source grounding, but it can now route work into a dedicated runtime, choose between direct reasoning and tool use, and return structured artifacts instead of only text. That is a bigger deal than it sounds. Once you separate planning from execution, you stop forcing one model call to do every job in the stack.
For most of its life, NotebookLM did all of that in a single model call that read your sources, reasoned, and answered, all inline. Underneath this launch, the same work now flows through three distinct layers:
Grounding. The work stays anchored to sources you provided or approved, exactly as it always has, and it remains the foundation everything else sits on.
Orchestration. The model decides what the task actually needs, whether that’s a direct answer, a prebuilt skill, or some custom code, and routes it accordingly.
Execution. The chosen path runs in a dedicated cloud environment and hands back a finished artifact, not just text.
The cleaner that contract between layers, the more capability we can add without the whole thing turning into a brittle prompt chain, with no single model call stuck being analyst, formatter, and renderer all at once.
The cloud computer behind the notebook
The most interesting piece is that execution layer. In practical terms, it’s a dedicated virtual machine with a set of skills the agent harness can reach for. Gemini can either write bespoke code for a one-off task, or call a pre-made skill that already knows how to produce a given type of file.
What changes here is that the model no longer has to improvise an entire workflow in one shot. It can choose a path and then delegate, which moves the interesting design question from “can it answer?” to “how well does it decide what to do?” An analytical task can drop down into code, a repetitive one can hand off to a skill that has done it before, and a request for a structured artifact can be packaged into the right format, with each one routed deliberately rather than crammed into a single response.
That deliberate routing buys repeatability as much as flexibility. When the same class of task gets handled the same way each time, you get something you can build a workflow on top of, rather than a result that happens to impress you once and then behaves differently the next time you ask.
What the runtime can produce
There’s more inside that environment than you might expect. Instead of a thin wrapper that knows how to emit a handful of file types, it’s a genuine computer with a real toolchain. There’s a full data stack (pandas, polars, DuckDB), proper modeling libraries for when a task needs them (scikit-learn, XGBoost, PyTorch, statsmodels), and rendering for nearly anything you’d want out the other side: matplotlib, Plotly and seaborn for charts; python-docx, python-pptx and openpyxl for Office files; reportlab and a LaTeX toolchain for typeset PDFs. It can OCR a scanned document (Tesseract), pull tables out of a messy PDF (pdfplumber), work with audio and video (ffmpeg, librosa, moviepy), do geospatial work (GeoPandas, Shapely), and reach for domain-specific libraries like QuantLib for finance or pydicom for medical imaging when a notebook calls for it.
I’m listing names on purpose, because the breadth is the point. The skills sitting on top of that stack are reusable capability modules shaped around tasks rather than file formats, and they cluster into a handful of things that matter:
Code execution: the backbone. It lets NotebookLM move from summarizing a source to analyzing it, computing metrics, testing assumptions, and surfacing patterns a plain-text response never could.
Web research and source discovery: for when you start with a loose idea instead of a finished source set, and need the system to go find and organize the material first.
Documents and reports:
pdf,docx, and markdown, the briefs and writeups where most real work actually lands.Charts and visualization: generated straight from the analysis, so the visual stays tied to the source instead of being rebuilt by hand somewhere else.
Spreadsheets and structured exports:
xlsx,csv, andjson, the bridge from a notebook answer into scripts, dashboards, and whatever’s downstream.Presentations:
pptx, turning source material into a communicable narrative without rebuilding the structure from scratch.Images: diagrams and supporting visuals (yes, Nano Banana) for when the work needs more than text.
What ties these together is that NotebookLM can now choose a file, a chart, a deck, or a structured export as the appropriate response to a given task, instead of leaving you to export and reformat everything by hand afterward. Plenty of tools can generate something that looks finished, but far fewer can do it while keeping the result tied back to the sources it came from, and that tie is the part I care about most.
What people actually did with it
I don’t have to speculate about the use cases, because I’ve now watched the first wave of real sessions come through, and the pattern is clearer than any roadmap deck. Two patterns in particular stood out to me.
The first is that people aren’t mostly coming to ask what their sources say. They’re coming to make something out of them, and that creative use is where the center of gravity sits: people doing real work in a long tail of languages, not running through a demo in English.
The second is how varied that work is. Here are a few representative examples of the sorts of things people can now do:
a law lecturer turning a dense set of property statutes into a structured graduate-seminar lecture
an analyst uploading a stack of quantitative-finance textbooks, then having the system test trading signals derived from market-positioning data
an instructor handing over a grading rubric and a batch of student assignments, and getting back a scored, formatted spreadsheet
someone turning a single research topic into a short video script, a slide deck, and a companion podcast, all in a language other than English
a reader sorting a pile of tech-conference announcements into clean thematic buckets
None of those is a “summarize my PDF” request. They’re people using NotebookLM to do the next step of the work, and in each case the whole thing stayed inside one grounded environment, which meant fewer tool switches, fewer places for the workflow to break, and an output that still traced back to the sources.
It’s changing the question people bring to the product, too, shifting from “What do these sources say?” toward “What should this become?”
Why this is the right shape
I’m betting on this direction because the division of labor finally feels right. NotebookLM stays grounded, which is non-negotiable, but the contract underneath is cleaner now: the model handles intent, the runtime handles execution, and the skills handle repeatable output. New capability slots into an existing layer instead of getting bolted onto the side.
Grounding is also what makes the execution layer credible in the first place. Once a product starts producing charts, spreadsheets, and decks, the thing readers need to trust is that those outputs still reflect the source, and faithful grounding is what NotebookLM has been built around from the beginning. Take it away and you’re left with another chatbot generating confident-looking files.
We’re early here, and not every routing decision will be right yet. But the architecture is the part I find most exciting. The system now has a real shape for turning knowledge work into finished outputs, which feels like a bigger change than the model simply getting better at conversation. More and more, it feels like a tool that helps you make the thing you came for, instead of stopping at an answer about it.
So I’ll leave you with the question I keep asking my own team: what would you build first, if your research tool could actually run the work?
— Trond