

The Great On-Device Migration
Gemma4 grabs the baton from Claude

Last week Google dropped Gemma-4 and it is a ridiculously awesome piece of AI engineering.
Gemma4
Everyone is obsessing over the flagship 31B model pushing the limits for open limits on the Arena AI leaderboard. This is insane for an open model, and pretty incredible for it to be available via a permissive Apache 2.0 License. But if you want to run Gemma at home, the real prize is the 26B Mixture-of-Experts (MoE) variant. You lose minimal ELO impact, but can easily run it on readily available hardware.

It packs 26 billion total parameters but only activates 3.8 billion per token. You get a massive 256K context window, and it to rank #6 overall among all open models. More importantly, it runs blazingly fast on a Mac Studio. Which I happen to have because my photography habit “required” I upgrade my old device last fall.
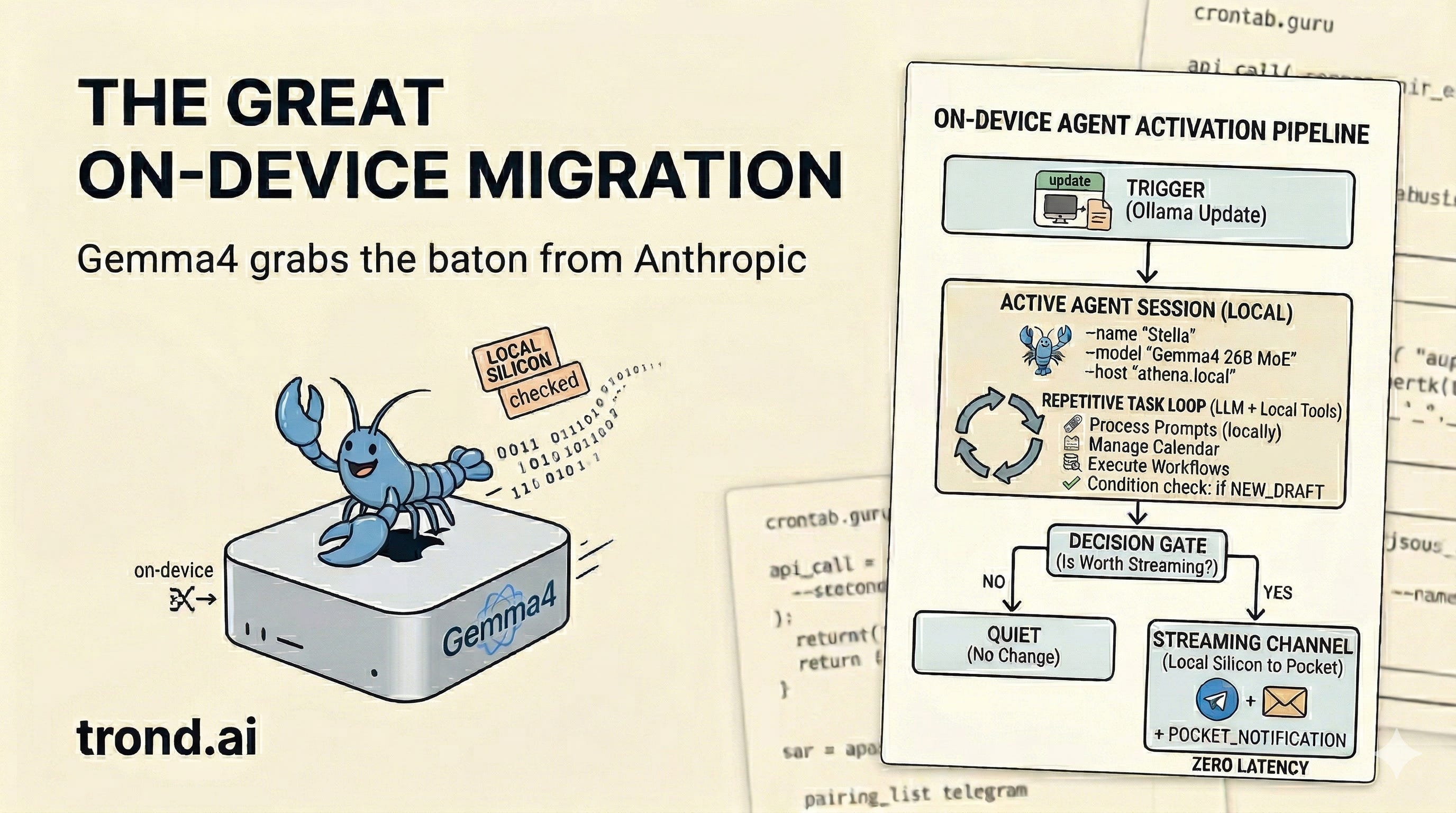
I’ve been itching to rip the cloud brain out of my OpenClaw system and wire up Gemma-4 locally since Tris told me about it a few weeks ago. But when a system is working just fine, it’s hard to justify breaking it just to see what happens.
Then Anthropic did me a massive favor: they killed API access for tools like OpenClaw on my current plan. I had been using a mix of Gemini and Claude in my system, but I was looking for an excuse to change so… twist my arm. I took the opportunity to pull the plug on Claude and move entirely to local silicon.
The Swap
You can’t just change a URL to swap an agent’s brain. But thanks to Ollama, it was pretty close. I’m on vacation this week with my family in London, so I needed to be able to do brain surgery from my phone.
So there I was, sitting on the Tube, dragging two tired kids back to our Notting Hill Airbnb, when I read the update on X from Boris Cherny about the Claude change. I fired up Telegram right then and got the process going. Kick off a command at a station, let Stella cook between stops while I was without service. Actually works pretty well!
We were returning from the British Museum after checking out the Parthenon marbles depicting the birth of Athena. (They really should be in Greece where they belong!) In the myth, Athena springs fully formed from the head of Zeus. I mention this because I named my Mac Studio Athena when we set her up last year. It feels poetic to have my own Athena, the Mac Studio node sitting 5,000 miles away in California, getting a new brain birthed directly from Gemini.
I started by having Stella remotely log into Athena to kick off an upgrade of Ollama to a version that supports the new Gemma-4 manifest format. Then it downloaded the ollama/gemma4:26b model. Took about 10 seconds at the Embankment stop on the Tube to get this started.
Next came the OpenClaw gateway patch for Stella on my Mac mini. I pointed the provider to http://athena.local:11434/v1 and set the default model to ollama/gemma4. A quick request at the Sloane Square stop.
I applied the config and restarted the system. Then I ran openclaw doctor from my phone via Chrome Remote Desktop. This was actually the hardest bit because it’s a bit of a pain to drive a terminal via CRD on a phone. The text is just so small! Got that done before we pulled into Notting Hill Gate.
After the process ran, everything just worked. Before we got back to the AirBnB.
Running on my own silicon
Now Stella is back online, processing prompts and executing workflows, completely untethered from the cloud.
The API bill is gone. The latency is near zero. And because it runs entirely on Athena, the data never leaves my house.
In fact, I started writing this article from my phone while my son Leo and I rode the train out to Richmond for a Ted Lasso tour. I’m finalizing it right now over a pint at The Prince’s Head (the pub from the show). While we ate, Stella formatted the draft and mapped out our train route to our next stop—a street photography tour near The Shard. It did all of this on local silicon 5,000 miles away, streaming the results right to my pocket with no delay.
Builder’s note: Some migrations take weeks. Some I completely whiff on. This one just worked. Watching your own AI agent run entirely on your own hardware is pretty awesome. You should try it.